
서론
현재 influxdb를 ec2에 container로 올려놨다.
사실 쿠버네티스에 pod로 올려서 관리한다면 참 좋겠지만, 여건 상 ec2에서 계속 사용하기로 하였다.
그렇기 때문에 influxdb 서버에 문제가 발생할 경우 자동 복구가 되게끔 세팅을 해보려고 한다.
사용할 것
AWS EC2 (CentOS 7)
AWS Cloud Watch
docker
rc.local 파일
- 기본적으로 docker가 있고 container를 띄울 준비가 된 환경에서 자동 복구 프로세스만 다룬다.
복구 프로세스
aws의 cloud watch 경보를 이용해 이상 탐지
-> ec2 자동 재부팅 ( cloud watch 경보 기능 )
-> centOS 7 자동 스크립트 실행으로 docker daemon 실행 및 docker container 복구
자동 실행 스크립트 생성
auto-recover.sh
sudo service docker start
sudo cd /influxdb-folder
sudo bash docker-restart.sh도커 데몬을 실행하고
미리 생성해뒀던 docker-restart.sh를 실행 하도록 하였다.
스크립트 시작프로그램 등록
1. root 계정으로 접근
2. cd /etc/rc.d/
3. vim rc.local
#!/bin/bash
su root -c /influxdb-folder/inftelegra/auto-recover.shsu root : root 계정으로
-c : 이 뒤의 커맨드를 실행하겠다.
------------------------------------------------------------
ec2 재부팅 후 재실행이 안 될 경우 시도 해볼 만한 것
상태 확인
sudo systemctl status rc-local
4. 실행 권한 주기
chmod +x /etc/rc.d/rc.local5. rc.local 실행
systemctl start rc-local.service6. rc.local 부팅 시 자동 활성화
# vi /usr/lib/systemd/system/rc-local.service
# 아래 내용 추가
[Install]
WantedBy=multi-user.target
systemctl enable rc-local.service
Cloud Watch 경보 생성
aws console로 가서 cloud watch로 들어간다.
새로운 경보를 생성해주자.
실제 환경에는 cloud watch agent를 깔아서 memory 사용량으로 경보를 생성할 것이지만,
우선 테스트로 CPU를 경보로 걸어줬다.

CPU가 90을 넘길 경우 경보.

경보 발생 시 알림을 주도록 하고
알림 대상은 AWS SNS에 미리 생성해 주어야 한다.

가장 중요한 EC2 재부팅 !
Auto Scaling도 가능하다고 한다.
경보 이름과 설명을 적어주면 생성을 할 수 있다.
테스트
이제 잘 작동하는지 ec2에 stress test를 진행해보자
yum install -y stress
stress --cpu 1 --timeout 600
top600초 동안 cpu를 최대로 사용

2cpu 머신이라 2 stress로 괴롭히기
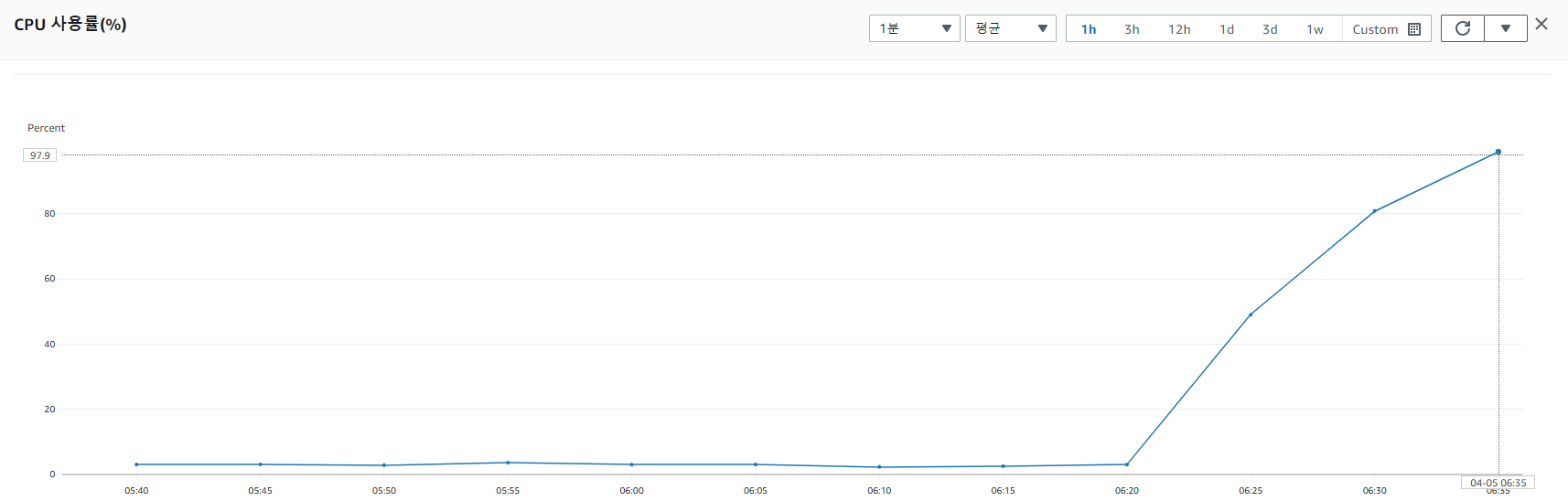
stress 실행으로 cpu 100%를 찍고 5분 뒤에 재부팅이 시작됐고
재부팅 후 약 3분만에 복구가 되었다.
물론 각 환경에 따라 다르지만 문제 발생 후 10분 안에 자동 복구가 되는 것을 확인 할 수 있었다.
'CS > Infra' 카테고리의 다른 글
| 무중단 배포 (Rolling, Blue/Green, Canary) (0) | 2023.04.13 |
|---|---|
| 쿠버네티스 공부 12일차 :: 스테이트풀셋에서 스토리지와 작동방식 (1) | 2022.12.01 |
| 쿠버네티스 공부 11일차 :: DB 파드는 어떻게 만들까? (스테이트풀셋) (0) | 2022.11.25 |
| 쿠버네티스 공부 10일차 :: 디플로이먼트 (0) | 2022.11.18 |
| 쿠버네티스 공부 9일차 :: 컨피그맵과 시크릿 (0) | 2022.11.09 |