CS/SQL
group by, aggregate function, order by
lovelyunsh
2024. 5. 28. 16:39
order by
- 조회 결과를 특정 attribute(s) 기준으로 정렬할 때 사용
- default는 ASC
- ASC : 오름차순, DESC : 내림차순
SELECT * FROM employee ORDER BY salary DESC; -- 내림차순
SELECT * FROM employee ORDER BY dept_id ASC, salary DESC; -- 2개 이상
aggregate function
- 여러 tuple의 정보를 요약시키는 함수
- COUNT, SUM, MAX, MIN, AVG 등이 있음.
- NULL 값을 제외하고 요약 값을 추출한다.
COUNT
SELECT COUNT(*) FROM employee; -- 일반적인 사용법
SELECT COUNT(dept_id) FROM employee -- 특정 컬럼을 지정할 경우 해당 컬럼에서 null이 아닌 튜플의 갯수를 가져온다.

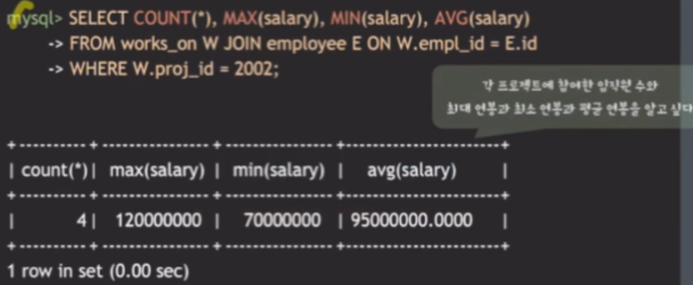
여러 aggregate 함수 사용.
GROUP BY
- 특정 attribute(s)로 그룹 지어 aggregate 함수를 적용할 때 사용.
- grouping attribute(s) : 그룹을 나누는 기준이 되는 attribute(s)
- grouping attribute(s)에 NULL 값이 있을 경우 NULL 값을 가진 tuple끼리 묶임.
- grouping attributes는 모두 select에 들어가야함. (W.proj_id)

HAVING
- group by와 함께 사용
- aggregate function의 결과 값에서 필터링을 할 때 사용

where vs having
실행 순서를 보면
- where 조건으로 모든 필드에 대해 필터링
- group by로 그룹화
- 그룹화 필드에서 having으로 필터링
having에 있는 조건이 where로 옮겨질 수 있는 것이라면,
where에서 필터링 하는 것이 group by의 연산을 줄이기 때문에 조금 더 효율적.
일반적인 실행 순서
- FROM
- JOIN ON
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
- LIMIT
위 글은 쉬운코드님의 데이터베이스 영상을 토대로 정리한 내용입니다.
https://www.youtube.com/watch?v=aL0XXc1yGPs&list=PLcXyemr8ZeoREWGhhZi5FZs6cvymjIBVe&index=1